
|
Movie Weaver: Tuning-Free Multi-Concept Video Personalization with Anchored Prompts
Feng Liang,
Haoyu Ma,
Zecheng He,
Tingbo Hou,
Ji Hou,
Kunpeng Li,
Xiaoliang Dai,
Felix Juefei-Xu,
Samaneh Azadi,
Animesh Sinha,
Peizhao Zhang,
Peter Vajda,
Diana Marculescu
CVPR 2025
project page,
arxiv,
We present Movie Weaver to support multi-concept video personalization.
|

|
Looking Backward: Streaming Video-to-Video Translation with Feature Banks
Feng Liang,
Akio Kodaira,
Chenfeng Xu,
Masayoshi Tomizuka,
Kurt Keutzer,
Diana Marculescu
ICLR 2025
project page,
arxiv,
code,
Huggingface demo,
Talk at Realtime Video AI Summit 2025,
We present StreamV2V to support real-time video-to-video translation for streaming input.
|

|
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
Feng Liang,
Bichen Wu,
Jialiang Wang,
Licheng Yu,
Kunpeng Li,
Yinan Zhao,
Ishan Misra,
Jia-Bin Huang,
Peizhao Zhang,
Peter Vajda,
Diana Marculescu
CVPR, 2024, Highlight
project page,
arxiv,
5min video,
We leverage the temporal optical flow clue within video to enhance the temporal consistency for text guided video-to-video synthesis.
|

|
Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
Feng Liang,
Bichen Wu,
Xiaoliang Dai,
Kunpeng Li,
Yinan Zhao,
Hang Zhang,
Peizhao Zhang,
Peter Vajda,
Diana Marculescu
CVPR, 2023
project page,
arxiv,
code,
Huggingface demo,
7min video,
1hour talk (chinese),
For the first time, we show open-vocabulary generalist models match the performance of supervised specialist models without dataset-specific adaptations.
|
|
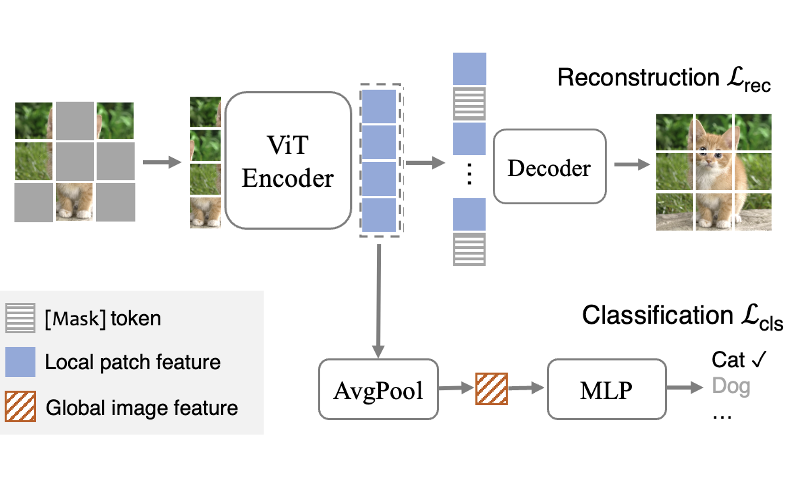
SupMAE: Supervised Masked Autoencoders Are Efficient Vision Learners
Feng Liang,
Yangguang Li,
Diana Marculescu
AAAI EIW, 2024, Best Poster Award
arxiv,
code,
award
SupMAE extends MAE to a fully-supervised setting by adding a supervised classification branch, thereby enabling MAE to effectively learn global features from golden labels.
|
|
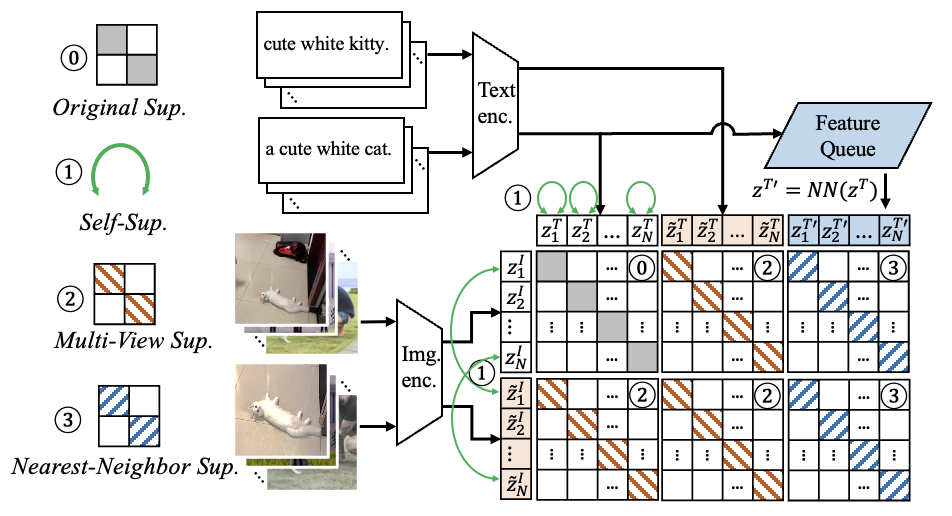
Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
Yangguang Li*,
Feng Liang*,
Lichen Zhao*,
Yufeng Cui,
Wanli Ouyang
Jing Shao,
Fengwei Yu,
Junjie Yan
ICLR, 2022
arxiv,
bibtex,
code,
video presentation
We propose Data efficient CLIP (DeCLIP), a method to efficiently train CLIP via utilizing the widespread supervision among the image-text data.
|
Selected Honors
- MLCommons ML and Systems Rising Stars by MLCommons 2024.
- Qualcomm Innovation Fellowship Finalist by Qualcomm 2024.
- UT Austin Engineering Fellowship by UT Austin, 2021 & 2023.
- Excellent Student Leader by Tsinghua University, 2018.
- National Scholarship by Ministry of Education of China, 2014 & 2015.
|
|
Mentoring
I’m fortunate to have worked with these talented students and collaborators:
-
Yang Zhou
— Undergraduate @ UT Austin → Ph.D. student @ CMU ECE (current).
-
Grace Kim
— Undergraduate @ UT Austin → Ph.D. student @ UPenn CIS (current).
-
Dennis Menn
— Ph.D. student @ UT Austin ECE (current).
|
|
Service
Reviewer of Journals: TPAMI, IJCV, TNNLS
Reviewer of Conferences: CVPR 2023/2024/2025, ICCV 2023, NeurIPS 2023/2024, ICLR 2024/2025, ECCV 2024, ICML 2025
|
|
